13 AI Content Detection Tools tested and AI Watermarks

Organizations, government agencies, and universities have a strong interest to determine if a piece of content was generated using a language model or AI text tool, needing a GPT Detector for handed in papers.
What percentage of this thesis handed in is actually authentic, written by a human?
Marketers and companies who purchase content may want to understand the extent to which the content they have acquired was generated using tools such as GPT3 or Jasper, Writesonic, or copy.ai. A GPT3 detector would be helpful, as GPT3 is the most common model used in these tools.
Website owners and SEO (search engine optimization) specialists want to ensure that Google correctly indexes their AI-generated content, despite being created using tools such as Jasper, Writesonic, or copy.ai. “Washing off” any potential GPT watermarks such tools could apply becomes a wish or need. The question remains if and when such AI content generator tools would in fact apply AI watermarks, or if they are able to decide.
For anyone wanting to audit content for ChatGPT as a major source, a “ChatGTP detector” would be required, so directly from the source, an “OpenAI Detector”. However, so far most detectors seem to be pure GPT2 detectors, even that “OpenAI Content Detector”, launched by OpenAI themselves.
Now we’ll look at state of the art in AI Content Detection and AI Content Watermarks. After all, if we don’t understand how it all works, how should we “bullet-proof” our AI content against detection?
How would a GPT3 detector or ChatGPT detector work? #
There are several ways to detect whether a piece of content was generated using a language model like GPT3, ChatGPT, or a tool like Jasper.ai, Writesonic, or copy.ai.
Some methods that could be used include:
- Checking for certain linguistic features or patterns that are common in machine-generated text. e.g. AI-generated text might have higher levels of repetitiveness or lack the complexity and variability of human-written text.
- Checking for specific formatting or structural features that are common in machine-generated text. e.g. AI-generated text might have a more uniform structure or lack the variety of formatting that is typical in human-written text. They sometimes look “too good to be true”.
- Checking for certain keywords or phrases that are commonly used in AI-generated text. That’s a lot harder already. In general there are statistically significant patterns known and detectable of which word combinations a model like GPT3 picks.
- Comparing the content in question to known examples of machine-generated text. This could be done manually or especially using machine learning techniques to analyze the content and determine its likelihood of being generated by a machine, again.
- It is important to know that both GPT3 and ChatGPT (GPT3.5) have a much richer vocabulary, and produce more complex output. This fact makes them harder to distinguish from human written content.
It is also important to note that detecting whether a piece of content was generated using a language model or AI tool is not straightforward. It may be challenging to determine the origin of a given piece of text definitively. Many trivial text blocks written by a human or copied/pasted from the web are often detected as likely AI-generated.
But that’s all very manual, still. But automation is in sight.
AI Content Detection Tools #
Which automated tools exist out there to detect AI content?
There are a couple of tools around that promise to detect content as AI-generated. Most of these tools are based on GPT2, not GPT3 or GPT3.5. Some tools don’t disclose what they are based on.
Here’s a brief list, with a quick “smoke test”, with commentary. We test each of them with a simple ChatGPT paragraph, as follows.
The Input from ChatGPT #
write a polite mail that a customer cannot come to the office for a coffee, because we're a remote-only company, but that we would be happy to do a zoom call for a chat.
which gave us, a quite trivial appealing
Dear valued customer,
Thank you for your interest in meeting with us for coffee. Unfortunately, as a remote-only company, we are unable to offer in-person meetings at this time.
However, we would be happy to schedule a zoom call for a chat instead. Please let us know a convenient time for you, and we will make sure to set it up.
We apologize for any inconvenience this may cause.
Sincerely, [Your Name]
ChatGPT Content Detection not working with GPTZero #
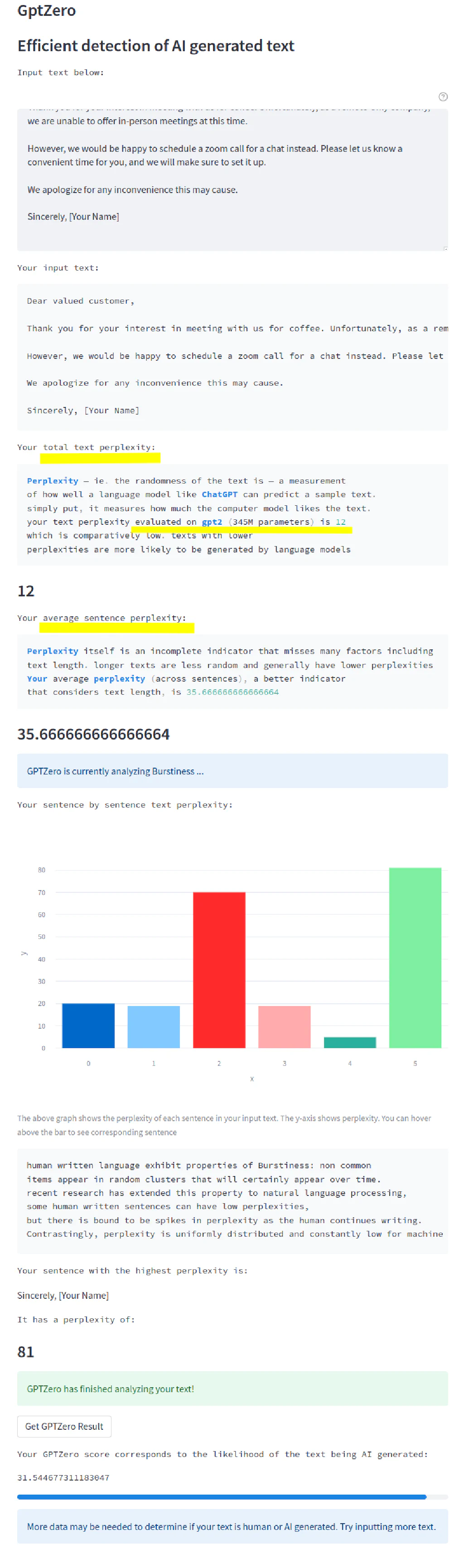
GPTZero is a very new, very hyped, and overloaded tool with a documented approach, but still based on GPT-2
It gave us a clear statement “yes there’s some AI” a bit lengthy:
Your GPTZero score corresponds to the likelihood of the text being AI generated
31.544677311183047
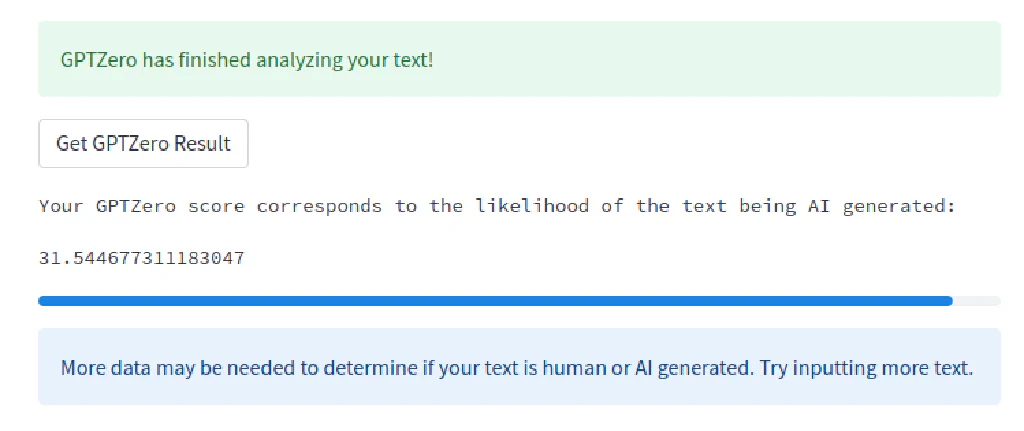
Now that’s not a variation of the PI Challenge (15 decimal places would be pretty lame anyways for a PI challenge).
That is 31.5% likelihood (and not 31500%) for it coming from AI. So just like Originality.ai* tested earlier, it doesn’t recognize it as significant 100% AI has written, but at least it doesn’t get “excited” calling the text 100% human.
Or, in short - F Fail for the AI Content Detector GPTZero. 31% AI is very off, too for a 100% AI text.
Props to the creator and the very useful details about the method on the page. This approach is unique and different from others and warrants more detailed tests.
Still exciting for a “New Years” project Edward! Kudos 🙏
Special note by Christoph: I strongly object to the use of derogatory language by certain mainstream media outlets to describe an individual who has demonstrated impressive capabilities in building a noteworthy system and collaborating with the BBC. It is inappropriate and disrespectful to belittle someone based on their age, and all individuals deserve to be treated with respect and dignity, regardless of their perceived level of experience or education.
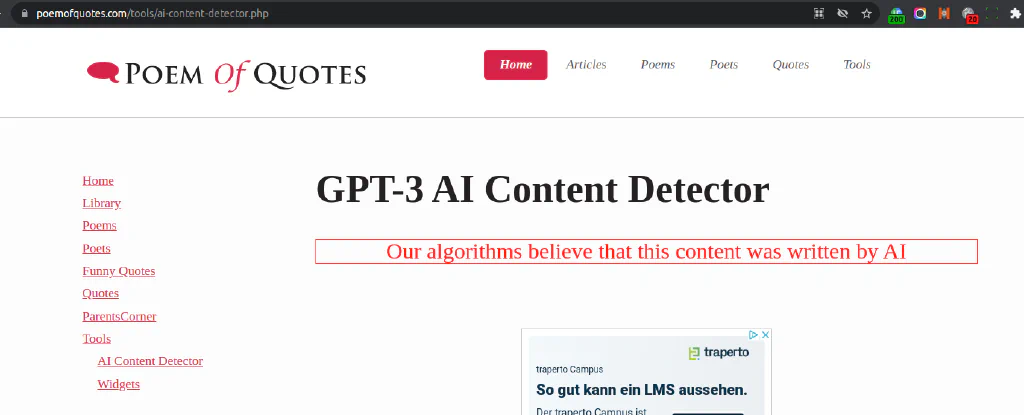
ChatGPT Content Detection Successful with PoemOfQuotes #
One of the two only tools that gave us a clear statement “Our algorithms believe that this content was written by AI” is the GPT-3 AI Content Detector by PoemOfQuotes.
It is limited to 4 free uses by users, but seems to have a fairly trivial “user” detection, so far.
The website is also full of ads and doesn’t provide a paid version for higher volumes. It’s unclear what their long term intentions are for their AI Content detector tool.
Another fairly new product offering seems to be an AI Content Detector by Crossplag.
A quick test reveals the same disappointing result like other GPT2 based AI content detectors.
AI Content Detector by Writer.com #
The AI Content Detector by Writer failed by 100%. We cannot call this result fantastic, at all - despite others reporting that this detection tool was updated to spot GPT3.
Maybe the (more expensive) GPT3 detection was enabled only for the reviewer at the time?

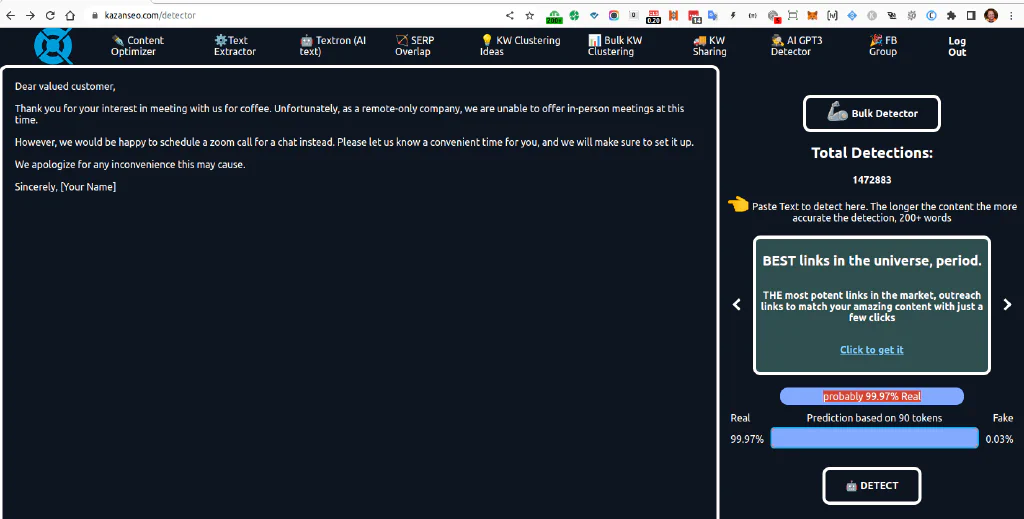
AI Content Detector by Kazanseo.com #
The AI Content Detector by Kazanseo failed by 99.97% as well. It says that our text email is probably 99.97% real, well it is 100% generated.
Positive detail here, however, is that it recommends to use long texts, and 200+ words for precise detection. This is the only tool that suggested, that our input data is maybe not “good enough”. However, counting that we only pasted 72 words is a trivial detail to implement, and in this case we would expect the tool to spit out an error message rather than an obviously wrong test result.
OpenAI GPT2 Content Detector on Huggingface #
The OpenAI detector for GPT2 content has been around for a while. And it’s built on top of the much smaller (1.5 billion) model GPT2, not GPT3 or even GPT3.5.
Still, many are using and pushing the hosting of it on Huggingface to the limits of Gateway timeouts.
Even for the use case “Detect GPT2 content,” the authors said: GPT-2 detects itself 81.8% of the time in easy cases.
In the case of fine-tuning, which means adapting a model like GPT2 (GPT3 can do that as well), the detection rate fell quickly to 70%, for GPT2 content.
Now imagine how unreliable the detection is for GPT3 or ChatGPT (GPT3.5, “da-vinci-003”).
And it does fail indeed, with only 0.03% fake detection.

AI Content Detection with GLTR - Giant Language model Test Room #
GLTR is a tool developed and published by MIT-IBM Watson AI lab and Harvard NLP is dated January 2022 and also based on GPT2.
It visually highlights words and how common these are. The histograms are interesting, but there’s no “Real-Human” score here.
When we use our ChatGPT example mail, we see many “not so common” words highlighted in yellow, red, and purple. These hint at a more active vocabulary of the writer and - measured by GPT2 standards a more original human source.
Well, not so correct here - either. As ChatGPT (GPT3.5) can generate a much richer, much more interesting text result, it also looks more human to a GPT2-based detection tool, not so surprising, is it?

AI Content Detection with ContentAtScale fails, too #
Another AI Detector by an AI writing service called ContentAtScale is also just as wrong as the previous detection tools we looked at.
We’ve not found any details on how this AI detector works yet. The pitch that the service provides undetectable AI content is interesting. Certainly, this provided tool is not helpful enough to verify that claim, so far.

AI Content Detection with Originality.ai #
We read that this tool should be able to detect the GPT3.5 and ChatGPT as of December 13.
We tested the service with the text blurb above, and Originality.ai* is the only tool that does not return an obvious wrong result.
But then, a 50:50 is also not exciting. But it prompts for more testing, which may follow.

AI Content Detection with Unfluff #
Another new product offering comes from Unfluff.io and their AI Content Detector, which is also offered as Wordpress Plugin.
A quick test reveals the same disappointing result like all the other GPT2 based AI content detectors.
What’s different tough is that they seem to plan to perform the tests on sentence basis, which would make a lot more sense for AI generated blogs or long-form content in general.
For our test test it just results in “100% no fluff” and says “No fluff sentences were found. Great Job!” - sorry, another fail.
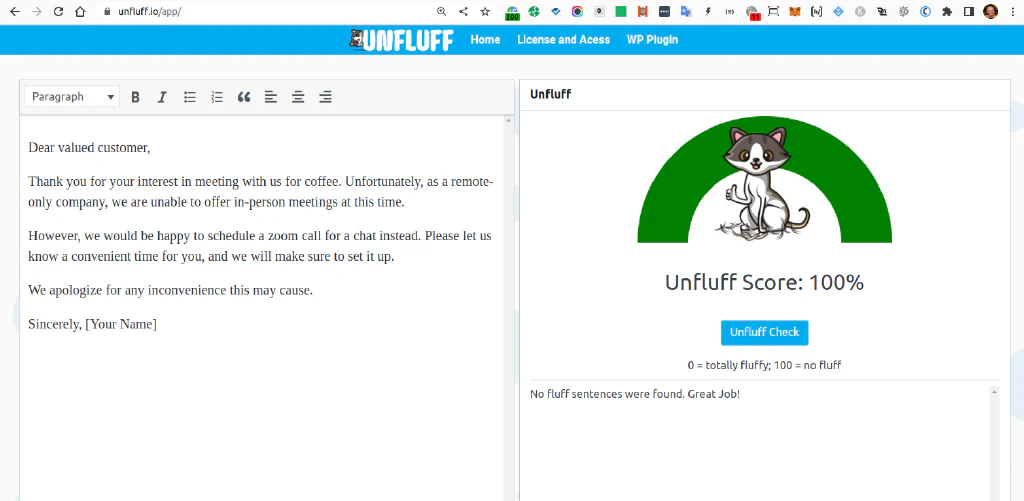
They do not declare clearly which AI models their detection is based on, but it seems to be just another wrapper around the outdated GPT2-based OpenAI detector.
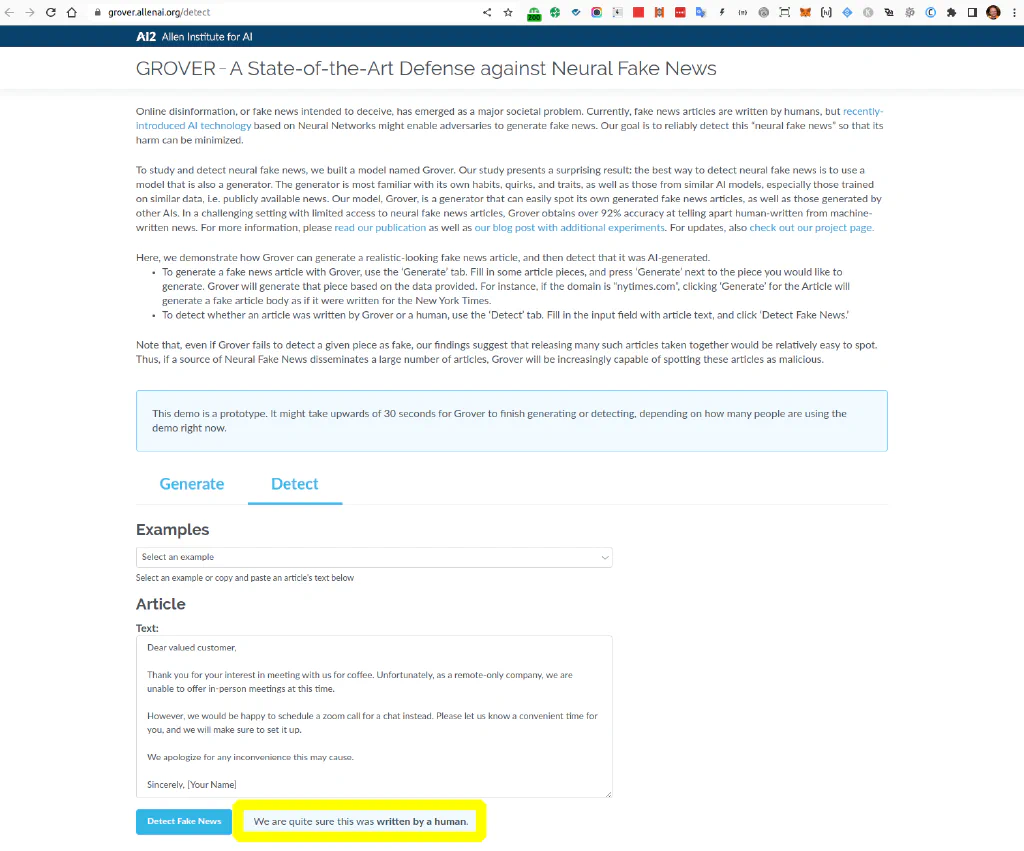
AI Content Detection with Grover #
The Grover AI Detector is promoted as “A State-of-the-Art Defense against Neural Fake News” by AI2 (Allen Institute for AI) developed by a team of researchers at the University of Washington. The paper however, is dated from 2019 - and it seems to show that it’s outdated already.
The statement “We re quite sure this was written by a human” for our quick test reveals the same disappointing result like with other (GPT2 based) AI content detectors, but this seems to work based on another model.
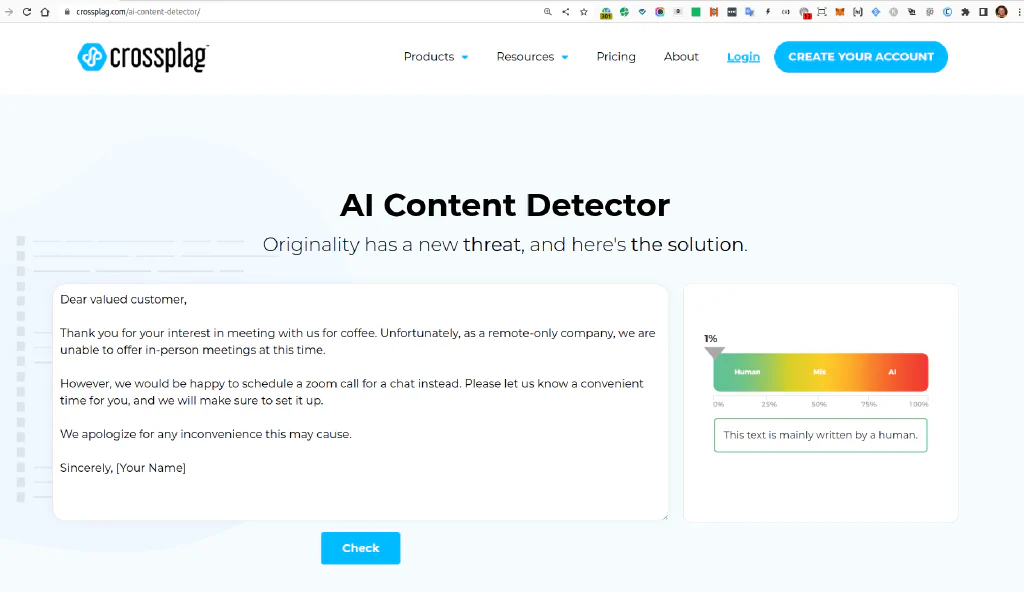
AI Content Detection with Crossplag #
Another fairly new product offering seems to be an AI Content Detector by Crossplag.
A quick test reveals the same disappointing result like other GPT2 based AI content detectors.
For our test test it just results in 1% and says “This text is mainly written by a human.” Sorry, fail.
The website was also built clearly as a competitor to Originality.ai* to target also the general plagiarism detection, offering a signup and email verification method, but is a bit flaky and seems to be incomplete or outright defect at the time of testing.
They do declare, that their AI Content Detector is based on a fine-tuned model of RoBERTa using the Open AI GPT2 dataset. This explains its limitations. The AI Content Detector is in testing phase and also not yet available for use by institutions, and generates results by analyzing up to 1,000 words at a time.
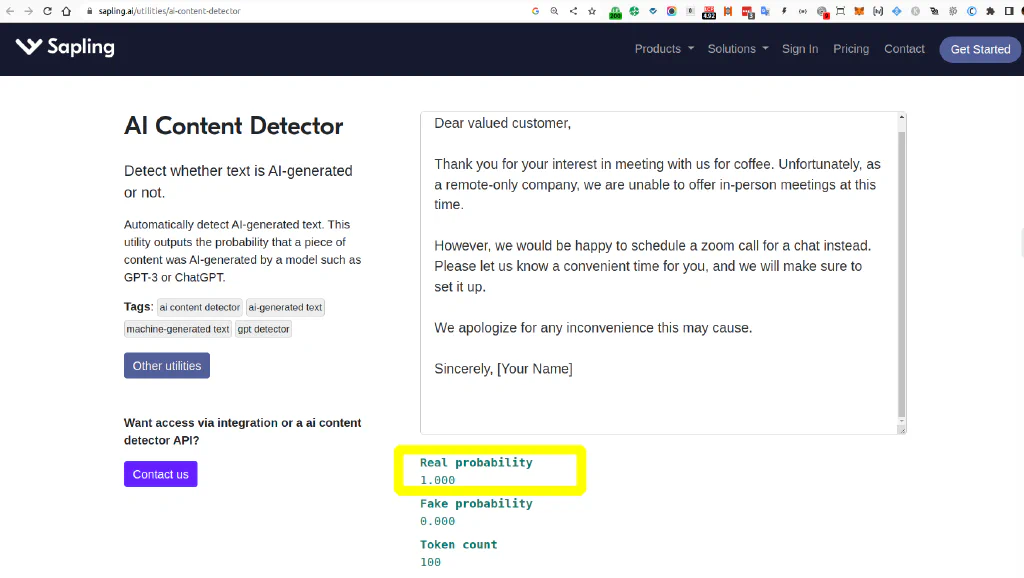
AI Content Detection with Sapling #
Also Sapling offer an AI Content Detector promising specifically that they output the probability that a piece of content was AI-generated by a model such as GPT-3 or ChatGPT.
A quick test reveals the same disappointing result like other GPT2 based AI content detectors, and I’m not seeing any hint at it being able to detect GPT3 or ChatGPT at all. It says 100% real to our test email, when it’s 100% fake.
AI Content Detection with Copyleaks.com fails, too #
This company provides a plagiarism checker similar to Copyscape. They also offer two ways to access their tool, and promise to detect AI-generated text.
- a browser-based app to detect AI content
- a browser extension to detect AI content
Both failed by 100% calling the unedited ChatGPT output “Human Text,” well, no.
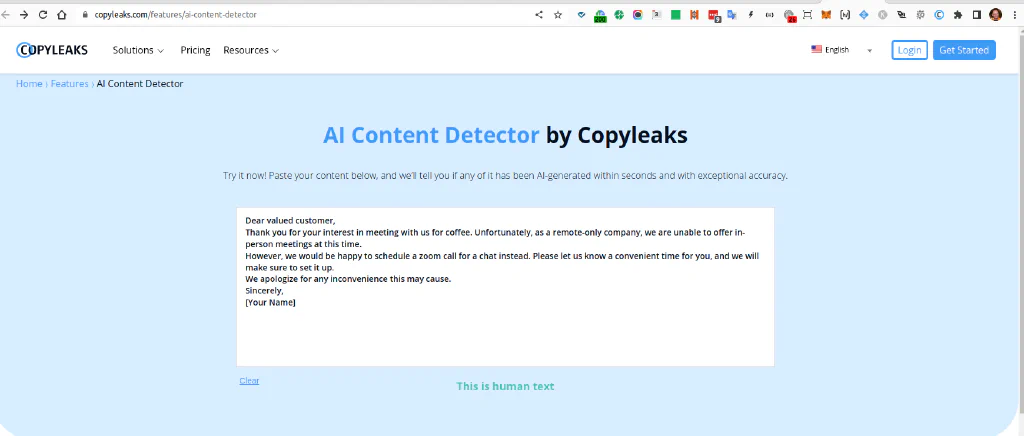
And the browser extension, getting the text copied directly from the ChatGPT website also says “human text”…. ¯\(ツ)/¯

So we can see, if you take an honest look at the quality and realism of today’s AI content output, there’s need to better AI Content Detection methods.
AI Watermarks #
What are AI Watermarks and how can they help? #
AI watermarking is a process or technology to ensure that content generated by an AI can be spotted as such.
Given the incredible power of ChatGPT, there’s been multiple outcries and demands for AI watermarking by many entities and journalists. Reddit is full of professors asking, “How can I spot this?”.
OpenAI has already experimented with watermarking and built a prototype, according to Scott Aronson, an AI genius.
My main project so far has been a tool for statistically watermarking the outputs of a text model like GPT.
Basically, whenever GPT generates some long text, we want there to be an otherwise unnoticeable secret signal in its choices of words, which you can use to prove later that, yes, this came from GPT. We want it to be much harder to take a GPT output and pass it off as if it came from a human.
So Watermarking works by using statistically significant word combinations, successfully already starting in snippets from 100 words. OpenAI’s text watermarking prototype already works, according to Scott.
In the plainest English, after the GPT model has generated a response, there will be a layer on top that shifts words/tokens very slightly and consistently. This is the output that will be given to the user (via API or Playground).This output can be measured and checked later by OpenAI/govt/potentially others.
A language model is software that processes input and generates output as a string of tokens, which can be words, punctuation, or other elements. It uses a neural network to generate a probability distribution for the next token to generate based on the previous tokens. The output is selected by sampling from this distribution, with a slight random element added through a “temperature” parameter. The “temperature” defines how much “creativity” or randomness is in the output; the higher the crazier the result.
To watermark AI Content, the next token is selected using a pseudorandom function with a secret key, known only to the provider like OpenAI, rather than purely randomly. This allows for creating a hidden bias in the output based on a function of the tokens, which can be computed if the key is known. So if you have that secret watermark key, you can then spot those footprints in the output text, the watermarks. Scott says it works pretty well already.
It seems to work pretty well—empirically, a few hundred tokens seem to be enough to get a reasonable signal that yes, this text came from GPT. In principle, you could even take a long text and isolate which parts probably came from GPT and which parts probably didn’t.
Why AI Watermarks in the first place? #
We are currently looking at GPT3 and GPT3.5, which has a circa two years old technology.
We know that Google’s PalM model (540b) outperforms these models by far.
And we also know that GPT4 is around the corner, and it is said to “Convert Water to Wine,” so good.
- GPT3 has 175 billion parameters
- GPT4 supposedly will have 100 trillion parameters (hearsay)
That’s about 500x bigger. Hearsay and illustration below by Charly.
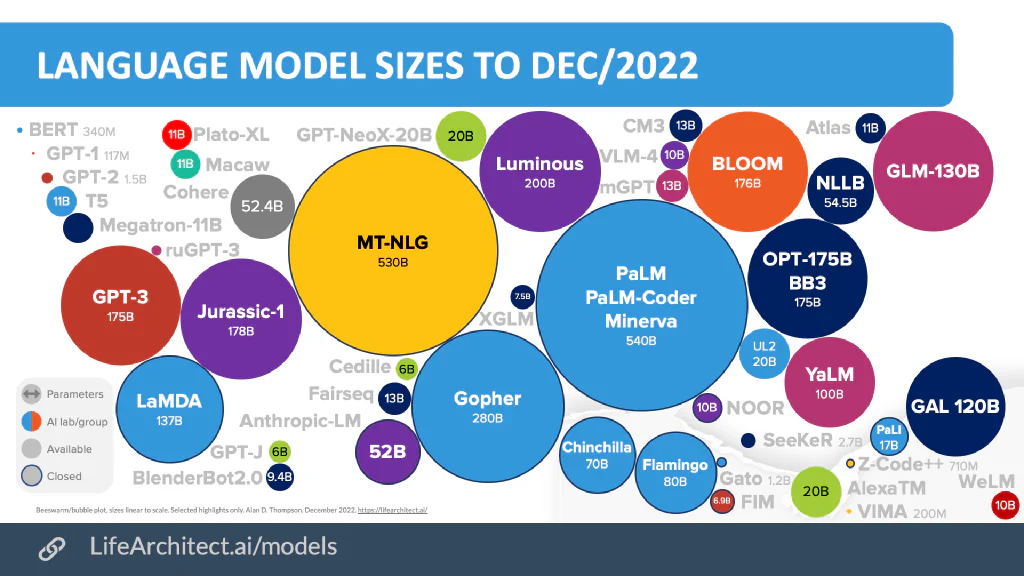
In the grand scheme of things we see there are a LOT of different large language models, either open or closed, or soon open. This landscape by by Dr. D Tomphson illustrates where we are heading, an endless mix of models will be possible.
With all those models, it is likely that it will become a legal requirement for large language model (LLM) providers to introduce AI watermarking. Or at least an ethical one. It seems China has already introduced such bans on AI generated works without clear watermarking.
Where are we today with AI watermarking? #
The current state of things is that the most potent large language models are held closed and are not open. Even the GPT3 by OpenAI is not open but closed source.
We have to assume that Google has long been working on footprinting AI content for its ranking systems.
For example, the number of skills and resources at Google shown in the 540B models PalM (vs. 175B GPT-3).
It is still unclear who and when will launch which AI watermarking technology - and who gets access to it. The current AI Content Detection tools could be more robust at best, more accurate, and reliable - but give us an idea.
Here are some interesting reads on AI Watermarking:
- Good discussion on the topic AI Watermarking in general, not just text. Difference between model watermarking and dataset watermarking.
- Did a robot write this? We Need Watermarks to Spot AI
- Does AI content need transparency to protect society?
- China Targets AI-Generated Media With New Watermark Requirement
Author Attribution and Author Vector #
What is Author Attribution? #
Author attribution “is the task of identifying the author of a given text from a (given) set of suspects.” This is a problem that can readily be framed as a text classification task, “where author represents a class (label) of a given text.”
Source: Mohsen et al. (2016) DOI:10.1109/ICMLA.2016.0161
Author attribution is a subfield of Natural Language Processing (NLP) and is very closely related to authorship verification, authorship identification, and authorship verification. AI Watermarking tries to tackle a very similar, albeit more trivial problem, instead of trying to answer the question
Which of these millions of humans wrote this text? it would just ask Which of these couple hundred large language models (GPT3, GPT4, etc) wrote this text, or which parts of this text?
What is an Author Vector? #
An Author Vector is a numercial vector describing that a document (or a part of it) was written by a particular author. That sounds usefur for our purposes, doesn’t it?
Google has been granted US Patent: 10,599,770 for “Generating author vectors” in 2020.
- the full Author Vector Google patent can be read here
- Bill Slawski explained the Author Vector patent on SEJ (Visit with Adblocker recommended)
- and furthermore here how Google can even imitate an author with Author Style Transformations and related Patent 10,083,156 “Text classification and transformation based on author”
All these patents and methods are designed to work on a single document, splitting it into sectionn and even (parts of) sentences.
More work in the field of Author Attribution #
There’s a lot more interesting work in the field of Author Attribution, for example these papers (all PDFs):
- Deep Learning based Authorship Identification by Qian et. al.
- Authorship identification using ensemble learning by Abbasi et. al. 2022
- A new method of author identification in short texts by Vijayakumar et. al. 2019
- Machine Learning for Author Attribution by Hayes 2018
so this is a topic not limited to Google or SEO, and it also not new.
The attempt to identify authors for (parts of) texts is not new, but has gotten a whole new emergency now that apparently most freelance writers try to pass off AI content as their own.
AI watermarking is one possible solution on a very broad level, but if you have a system to map authors and their writing style, you can also use that to detect AI content.
Does Google devalue content written by and detected as AI? #
It needs to be made clear whether Google specifically devalues content written by AI or is detected as such. Google has taken a clear stance on (trivial) AI content being against their guidelines and have “outlawed” such content automation techniques. Google has also made clear, that they have the tools to identify AI content and will take action against it, in the context of plagiarism from other websites:
we have many algorithms to go after such behaviors and demote site scraping content from other sites.
Google’s search algorithms are designed to surface relevant and helpful quality content to users, regardless of whether a person or an AI created it. However, it is important for content creators to follow Google’s guidelines and produce high-quality, original, and helpful content in order to rank well in search results.
Suppose Google determines that a website is using low-quality or spammy tactics to try to improve its ranking. In that case, it may apply penalties that can negatively impact the site’s visibility in search results. This has been the case for the past twenty years with updates as popular as the Panda or Penguin Updates.
We can be quite sure that Google has everything they need to detect AI content, outperforming currently public available technology.
Does Google devalue links from AI written content? #
We also don’t know yet if Google devalues links from AI-written content.
Again, Google’s algorithms are designed to assess the quality and relevance of links as a factor in determining the ranking of websites in search results.
The value of a link is not determined solely by the source of the content, but also by your own website - the target where that link points to. A link is a connection from Source A to Target B.
Google considers various factors when evaluating links, including the relevance of the linking page to the linked page, the overall quality of the website hosting the URL containing the link, and the overall authority and trustworthiness of the linking website. NB: they always say there is no “Site Authority” metric inside their system for the whole domain. Yes, we can be sure that the naive implementations from outside tools do not come close to Google’s internal plethora of metrics. But of course, there’s an overall “weighting” of a website’s trust.
When it comes to links and link building, in general, it is essential to focus on building high-quality, relevant, and natural links from original and helpful content in order to improve the visibility and ranking of a website in Google’s search results. This hasn’t changed.
Limitations of this post #
Sample size = 1 for the product tests #
Yes, product testing needs a bigger sample size than 1. We need to test products or anything more profound to see how they perform and get a reliable verdict. What we did here is also referred to as a minimal “smoke test” in software development.
A smoke test is a type of test used to quickly verify that the most critical functions of a software program are working correctly. A smoke test aims to identify any significant problems with the software as early as possible in the development process.
If the smoke test is successful, the software is likely to be in good working order and ready for more thorough testing. If the smoke test fails, it means that there are severe problems with the software that needs to be addressed before it can be released.
In our case so far, all products have failed the smoke test.
Nevertheless, we plan to perform more tests for each tool.
Test Input Email vs. “Blog Post” (long form content) #
We used an email as test input, which is a concise text. We should test with longer texts and blog posts, which are longer and more complex.
The complexity of the AI detectors, and also the testing of that, is that:
- blog posts can be anything from 300 to 12000 words, typically.
- blog posts can be written by humans or AI mixed, so often combine elements, paragraphs, or even switch in the sentence.
- parts of blog posts are often rewritten using tools like Grammarly, which can correct and rephrase parts of the text.
- creation of blog posts is split up into smaller segments by AI writers like Copy.ai or Writesonic and then combined into a blog post.
Therefore detection of AI content in blog posts is more complex than it seems. Looking at long-form content differs significantly from the short-form, AI-generated snippets.
When is a blog post compiled from parts “written by AI”, and to which percentage?
The expectation to copy/paste a 5000-word post into one of those tools’ text boxes for AI Content Detection could be possible, but no tool, so far, seems to split up the text into smaller segments and then detect AI content in each segment.
The Email of 76 words seems a good test input for AI Content Detection, resembling a small part of a much bigger blog posts in this case.
All of the above mentioned methods and papers regarding Author Identification are based on such separation into short-form content, i.e. paragraphs or sentences. Nobody in the scientifi field of NLP seems to attempt to give a whole document one score Human Vs. AI, so all the tools tested seem to start with wrong assumptions.
Nevertheless, we plan to perform more tests with blog posts.
Conclusion #
What AI Content Detection tools can we use today? #
So far, only GPTZero, PoemOfQuotes and Originality.ai* have something worth exploring. More tests are needed to determine how good they are or if it’s always a 50:50 human-to AI-verdict or a randomish “human percentage” that is worthless in the end.
Currently, the results are not satisfying yet, and we would still recommend
- manual reviews of content
- publishing and waiting for Google indexing to decide if the content is “good enough”, and worthy of getting indexed
On the other hand, blatantly cheap AI content can be detected to some extent, which is a start.
Is there an AI Watermarking technology out there to use? #
No, not yet.
Are there other approaches not yet tested? #
Yes, a trained model that used ten-thousands of human quality rater inputs seems like a novel approach worth exploring. Some scientists worked on that, and there’s a lot more to learn.
Frequently Asked Questions (FAQ) #
What is AI Watermarking?
AI watermarking is a process or technology to ensure that content generated by an AI can be spotted as such.
Given the incredible power of ChatGPT, there’s been multiple outcries and demands for AI watermarking by many entities and journalists. Reddit is full of professors asking, “How can I spot this?”.
OpenAI has already experimented with watermarking and built a prototype, according to Scott Aronson, an AI genius.
Is there a specific ChatGPT Watermark?
No. This was implied by the click-baity title on some articles, like this article on Search Engine Journal published after this article, but does not exist.
OpenAI is the company behind GTP2, GTP3, GPT3.5 and also ChatGPT.
They have not released any watermarking technology yet, and non specific to ChatGPT.
When OpenAI release their watermarking, it will get a GPT3 Watermark, a ChatGPT Watermark, a GPT4 Watermark, and so on.
How does OpenAI want to watermark it's AI output?
Watermarking works by using statistically significant word combinations, successful already starting in snippets from 100 words.
OpenAI’s text watermarking prototype already works. In the plainest English, after the GPT model has generated a response, there will be a layer on top that shifts words/tokens very slightly and consistently. This is the output that will be given to the user (via API or Playground).
This output can be measured and checked later by OpenAI/government/potentially others.
Can search engines detect the difference between GPT3 and Human content?
It really looks like Google is able to detect the difference between GPT3 and human content. The reason for that is that even simple GPT-2 models are able to detect some content as generated, but they are too weak. Originality.ai* says they can reliably detect GPT-3 content, and indeed some examples look much better.
But Google themselves have bigger LLMs than GPT3, like PalM(560B vs. 175B parameters) so it is very likely that they are even better at generation, and detection.
What is AI Watermarking?
AI watermarking is a process or technology to ensure that content generated by an AI can be spotted as such.
Given the incredible power of ChatGPT, there’s been multiple outcries and demands for AI watermarking by many entities and journalists. Reddit is full of professors asking, “How can I spot this?”.
OpenAI has already experimented with watermarking and built a prototype, according to Scott Aronson, an AI genius.
Is there a specific ChatGPT Watermark?
No. This was implied by the click-baity title on some articles, like this article on Search Engine Journal published after this article, but does not exist.
OpenAI is the company behind GTP2, GTP3, GPT3.5 and also ChatGPT.
They have not released any watermarking technology yet, and non specific to ChatGPT.
When OpenAI release their watermarking, it will get a GPT3 Watermark, a ChatGPT Watermark, a GPT4 Watermark, and so on.
How does OpenAI want to watermark it's AI output?
Watermarking works by using statistically significant word combinations, successful already starting in snippets from 100 words.
OpenAI’s text watermarking prototype already works. In the plainest English, after the GPT model has generated a response, there will be a layer on top that shifts words/tokens very slightly and consistently. This is the output that will be given to the user (via API or Playground).
This output can be measured and checked later by OpenAI/government/potentially others.
Can search engines detect the difference between GPT3 and Human content?
It really looks like Google is able to detect the difference between GPT3 and human content. The reason for that is that even simple GPT-2 models are able to detect some content as generated, but they are too weak. Originality.ai* says they can reliably detect GPT-3 content, and indeed some examples look much better.
But Google themselves have bigger LLMs than GPT3, like PalM(560B vs. 175B parameters) so it is very likely that they are even better at generation, and detection.
Table of Contents
Use the Cheat Code for AI today. Install AIPRM for free.
Just a few clicks away from experiencing the AIPRM-moment in your AI usage!
Popular AI Prompts
Summarise most important info
Summarize PromptsSummarise the text, highlight key points
Pen SEO-Friendly Article with a Single Click
Writing PromptsGet a 100% Unique SEO-Optimised Article of 1500+ words, complete …
Website Silo Planning
Keywords PromptsWhip up a website silo outline using a keyword or phrase, sparking …
Bloody Ripper Content From Hell
Writing PromptsChuck in Your Keyword or Title, Mate
As Seen On
Computer Woche DE
Upwork
Zapier
Seeking Alpha
Liverpool Echo UK
Daily Record UK
Mirror UK
ZDNet DE
The US Sun
What Our Users Say
Excellent!!
"I just started, but it seems very good work”

AIPRM: A Game-Changer, Revolutionizing Industries with Unmatched Precision!.
"Embracing the transformative power of AIPRM, where algorithms navigate the complexities of decision-making, is like witnessing innovation unfold in real-time. In a world of endless possibilities, letting these digital minds shine is a testament to the potential for progress beyond human intuition.”

AIPRM: A Game-Changer, Learning and Loving Every Moment!
"What an amazing tool! Loving using it and learning as I go. Thank you!”
